
Google’s web crawler, Googlebot, processes millions of web pages daily, helping build one of the most extensive indexes of online content. Without web crawlers, search engines would be unable to deliver relevant search results, making the internet far less accessible and organized.
Table of Contents
But what is a web crawler exactly? How do web crawlers impact website rankings and SEO? And why should website owners care about crawlers’ website activities?
In this in-depth guide, we’ll cover:
✅ What is a web crawler?
✅ How do web crawlers work?
✅ Why are web crawlers important for websites?
✅ Types of web crawlers
✅ Common challenges related to crawlers website activities
✅ How to optimize a website for web crawlers
Let’s dive in!
A web crawler (also known as a spider or bot) is an automated program that systematically browses and indexes web pages for search engines.
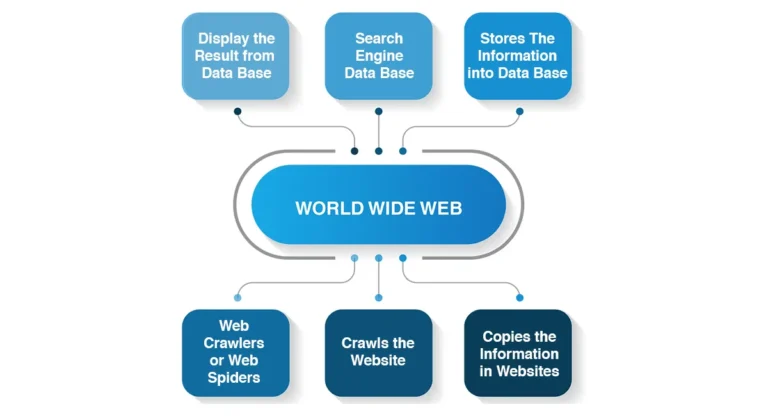
When you type a query into Google or Bing, the search engine doesn’t search the entire internet in real time. Instead, it pulls results from a pre-built index of web pages. Many businesses work with a trusted digital marketing agency to ensure their websites are optimized for better crawler indexing.Web crawlers are responsible for creating this index by:
Simply put, web crawlers are the backbone of search engines, ensuring that users get accurate and up-to-date results.
Web crawlers can positively or negatively impact a website depending on how well the website is structured. Let’s look at the pros and cons of crawlers website activities.
✔ Better Search Engine Visibility – If a web crawler successfully indexes your site, it increases the chances of your content appearing in search results.
✔ Increased Organic Traffic – Indexed pages can drive more visitors to your website.
✔ Updated Website Information – Crawlers ensure latest content is reflected in search engines, helping users find fresh data.
❌ Crawl Budget Limitations – Search engines allocate a limited number of crawl requests per site. If a site isn’t optimized, important pages may go unnoticed.
❌ Slow Loading Issues – If a website is too slow or unresponsive, crawlers may abandon the indexing process.
❌ Duplicate Content Problems – Web crawlers may index duplicate content, leading to SEO penalties.
A well-optimized website ensures web crawlers can efficiently scan and index pages, improving search rankings.
When we talk about crawlers’ website interactions, we refer to the way web crawlers access, analyze, and store a site’s content.
The more crawler-friendly a website is, the more likely it will be properly indexed and ranked.
Not all web crawlers serve the same purpose. Here are the main types:
These are the most common crawlers used by Google, Bing, and Yahoo to index pages. Examples:
✔ Googlebot (Google)
✔ Bingbot (Bing)
✔ Yandex Bot (Yandex)
SEO specialists use these crawlers to analyze website performance. Examples:
✔ Screaming Frog SEO Spider
✔ Ahrefs Bot
✔ SEMrush Bot
Companies use these crawlers to collect data for business insights. Examples:
✔ Amazonbot (Amazon)
✔ Facebook Crawler (Meta)
Some bots extract website data for unauthorized use. Examples:
❌ Content scrapers – Copy content without permission.
❌ Spam bots – Post spam comments on blogs and forums.
Website owners must monitor web crawler activity to protect their data and improve search rankings.
A well-optimized website helps search engines index content efficiently. Here’s how:
Example:
Copy code
User-agent: *
Disallow: /private-page/
Allow: /public-page/
Even well-optimized websites can face crawler-related challenges. Some common issues include:
Cause: Blocked by robots.txt or missing sitemaps.
Solution: Check robots.txt and submit sitemaps in Google Search Console.
Cause: Excessive bot activity.
Solution: Limit crawl rate using Google’s settings or server rules.
Cause: Lack of canonical tags.
Solution: Use canonical tags to guide crawlers.
Cause: Unprotected data.
Solution: Use copyright notices and block suspicious bots.
By regularly monitoring web crawler activity, website owners can prevent SEO issues and improve rankings.
Web crawlers play a crucial role in how websites are discovered, indexed, and ranked by search engines.
✅ They help users find relevant content quickly.
✅ They allow businesses to gain organic traffic.
✅ They support SEO efforts by ensuring pages are properly indexed.
However, not all crawler activities are beneficial. Website owners should:
✔ Optimize their sites for search engine crawlers
✔ Monitor bot activity to prevent malicious attacks
✔ Use best practices to maximize SEO performance
By understanding what a web crawler is, how crawlers website activities function, and how to optimize for them, businesses can enhance their digital presence and grow online visibility.
Now that you know all about web crawlers, is your website optimized for better indexing?
Nirbhay Chauhan is a Performance Marketing and ROI Specialist with expertise in SEO, PPC, and media planning. With a passion for data-driven strategies, Nirbhay helps businesses scale by optimizing their marketing efforts to deliver measurable results. His extensive experience in driving online growth and maximizing ROI makes him a trusted partner for businesses looking to elevate their digital presence.
